This is an old revision of the document!
Table of Contents
Using the Cluster
ILRI's high-performance computing "cluster" is currently composed of 7 dedicated machines:
- hpc: main login node, "master" of the cluster
- taurus, compute2, compute04: used for batch and interactive jobs like BLAST, structure, R, etc (compute04 has lots of disk space under its
/var/scratch) - mammoth: used for high-memory jobs like genome assembly (mira, newbler, abyss, etc)
- compute03: fast CPUs, but few of them
- compute05: batch jobs, has the fastest processors (AMD EPYC)
To get access to the cluster you should talk to Jean-Baka (he sits in BecA). Once you have access you should read up on SLURM so you can learn how to submit jobs to the cluster.
How to Connect to the Cluster
In order to launch computations on the HPC or even just to view files residing in its storage infrastructure, users must use the SSH protocol. Through this protocol, users gain command-line access to the HPC from an SSH client software installed on their own machine (e.g. a laptop, desktop or smartphone). Depending on the operating system you are using on the computer from which you want to establish the connection, the procedure differs:
If you are running MacOSX (on Apple computers) or any GNU/Linux distribution
Those operating systems are part of the large family of UNIX systems, that almost invariably contain an already-installed SSH client, most often some flavor of the OpenSSH client. Just open a terminal emulator and run the command ssh username@hpc.ilri.cgiar.org, where your replace username with your own username on the HPC (as communicated by the person who created your account there).
If the above doesn't work, then you probably have to install an ssh client. It suffices to install the SSH client only, no need for the SSH server: that one would be useful only if you want to allow remote connections into your computer. For instance, you can read about instructions to install openssh-client on Ubuntu GNU/Linux.
Cluster Organization
The cluster is arranged in a master/slave configuration; users log into HPC (the master) and use it as a "jumping off point" to the rest of the cluster. Here's a diagram of the topology. For each server, we mention the number of CPUs and the year it was commissioned:

Detailed Information
| Machine | Specifications | Uses | 1 hour status |
|---|---|---|---|
| taurus | 116 GB RAM 64 CPUs | batch and interactive jobs Good for BLAST, structure, R, admixture, etc. |  |
| mammoth | 516 GB RAM 8 CPUs | batch and high-memory jobs Good for genome assembly (mira, newbler, abyss, etc) |  |
| compute2 | 132 GB RAM 64 CPUs | batch and interactive jobs Good for BLAST, structure, R, etc. |  |
| compute03 | 442 GB RAM 8 CPUs | batch and high-memory jobs Good for genome assembly (mira, newbler, abyss, etc), mothur |  |
| compute04 | 48 GB RAM 8 CPUs 10TB scratch | batch jobs Good for BLAST, structure, R, etc, that need lots of local disk space (/var/scratch/) |  |
| compute05 | 384 GB RAM 48 CPUs 1.6TB scratch | batch jobs Most recent AMD EPYC CPUs, good for BLAST, structure, R, etc | 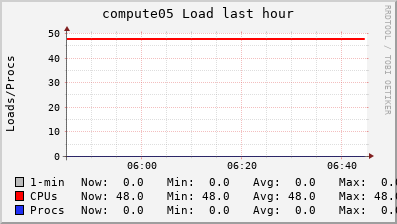 |
Backups
At the moment we don't backup users' data in their respective home folders. We therefore advise users to have their own backups.